The Import Feeds module enables bulk data import for any entity in AtroCore, including related entities and their creation. Import feeds use the AtroCore REST API, ensuring data validation follows the same rules as manual record creation.
Data import can be performed:
- Manually – using configured import feeds directly
- Automatically – via scheduled jobs
The free module supports file-based imports (CSV, Excel, JSON, XML). Additional modules extend import feed capabilities:
- Import: Database – MSSQL, MySQL, PostgreSQL, Oracle, HANA database imports
- Import: HTTP Request – REST API and HTTP request imports
- Import: Remote File – automated imports from FTP, sFTP, or URL sources
- Synchronization – orchestrates multiple import and export feeds for complex data exchange
Administrator Functions
After installation, two entities are created: Import Feeds and Import Executions. These can be enabled/disabled in navigation menu and favorites, with access rights configured as for other entities. Layout configuration is not available for these entities.
Users must have the following permissions configured via Roles (Scopes panel): Import Feeds, Import Execution and Files, as well as at least Read permission for Folder, and Storage. Without these, feed import execution will be denied. In Access Control List strict mode, these permissions must be granted explicitly — they are not given by default.
User Functions
Users can work with import feeds according to their assigned role permissions after administrator configuration.
Import Feed Creation
Navigate to Import Feeds and create a new import feed.
Details Panel
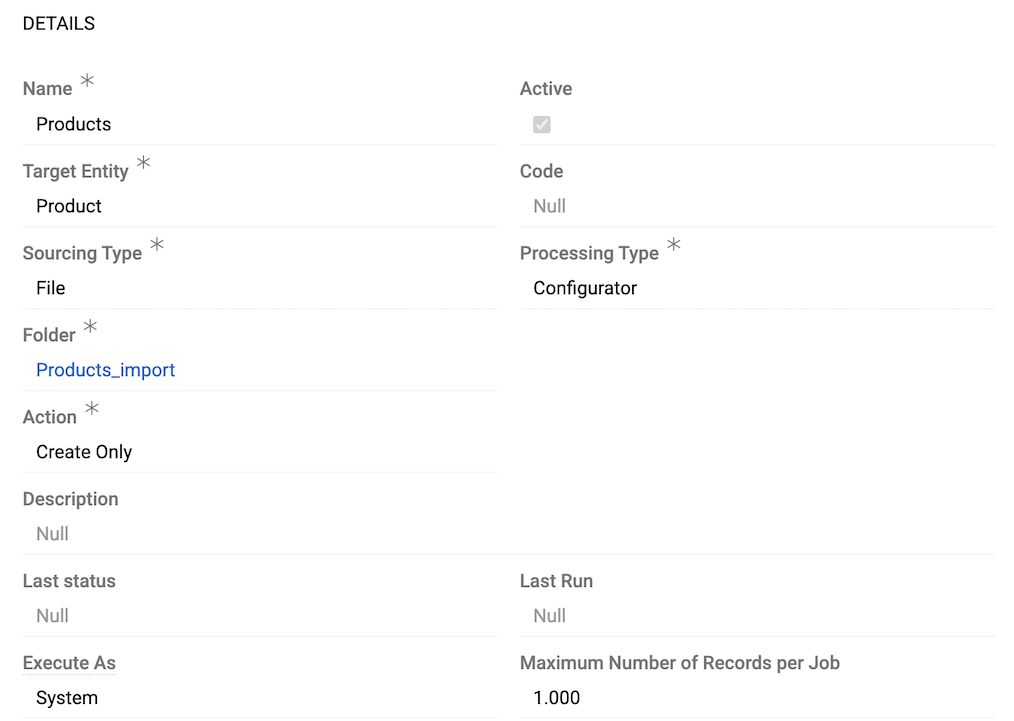
Define main feed parameters:
-
Name – import feed identifier
-
Active – enables/disables the import feed
-
Target Entity – select entity for imported data from available entities
-
Code – unique import feed code
-
Sourcing Type – import feed type (cannot be modified after creation). Default: File; other types are available upon installation of additional modules.
-
Processing Type – default: Configurator (extensible by developers - see Processing Type for details).
-
Folder – the folder where files created by this import feed will be stored. This field is required.
It is recommended to create a separate folder for each import feed to keep files organized and easier to manage.
-
Action – defines import behavior:
- Create Only – creates new records only
- Update Only – updates existing records only
- Delete Only (found records) – deletes records present in import data
- Delete Only (for not found records) – deletes records absent from import data
- Create and Update – creates new and updates existing records
- Create and Delete – creates new and deletes absent records
- Update and Delete – updates existing and deletes absent records
- Create, Update and Delete – full synchronization
-
Description – usage notes and reminders
-
Execute As – user context for import execution:
- System – runs with system-level permissions
- Same user – runs with current user permissions. When selected, the corresponding user appears as a link following System in the Created and Modified fields in the Summary panel of the Side View for changed records.
-
Maximum Number of Records per Job – limits records per job for performance optimization
Data Sourcing
The Data Sourcing section is type-dependent—each import feed type has its own specific settings. This article describes settings for the File type (the default). For other types, see the respective module documentation:
- Import: Database – database connection and SQL query settings
- Import: HTTP Request – REST API and HTTP request settings
- Import: Remote File – FTP, sFTP, and URL source settings
File type settings:
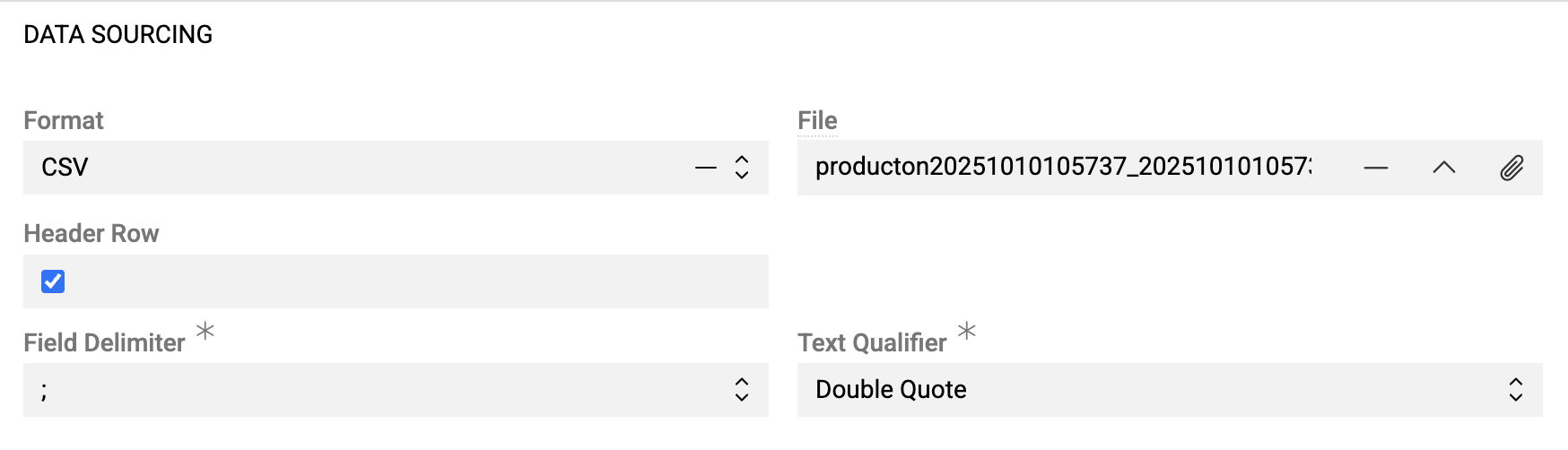
- Format – file format: CSV, Excel, JSON, XML
- File – upload import file or sample for configuration (UTF-8 encoded)
CSV specific:
- Header row – activate the checkbox if column names are included in the import file, or leave it empty if the file has no header row with column names
- Field Delimiter – field delimiter used to separate fields. Options:
,,;,/t. Default value is; - Text Qualifier – options:
Double Quote,Single Quote
Excel specific:
- Sheet – select worksheet for import
- Header row – activate the checkbox if column names are included in the import file, or leave it empty if the file has no header row with column names
If the XLS file is too large to import, you can convert it to CSV.
JSON/XML specific:
- Root Node – element containing all records
- Excluded Nodes – elements to exclude from source fields
- Array Nodes – nodes treated as leaf elements
Data Processing
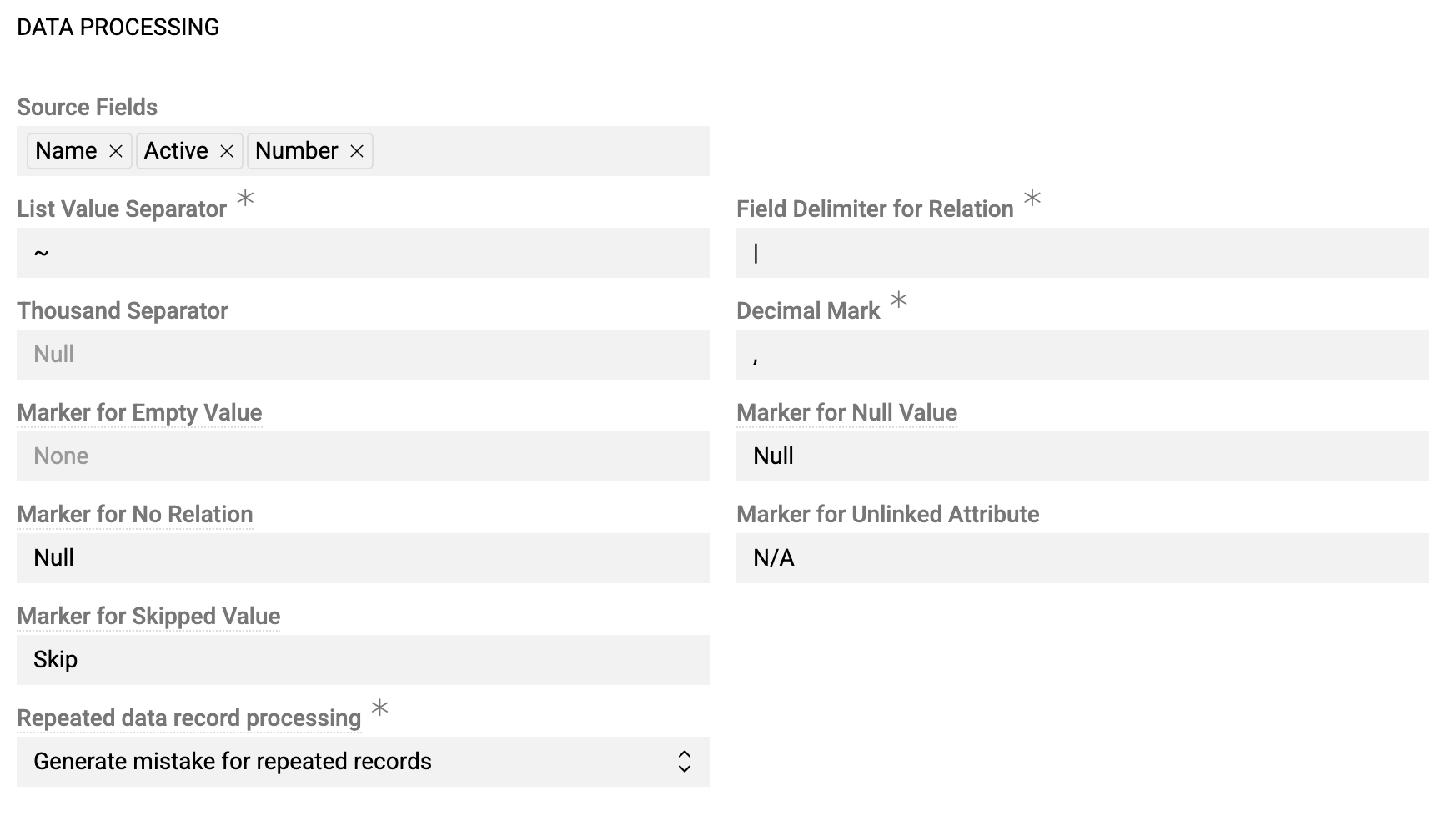
- Source Fields – this field is initially empty. After uploading the file in the
Data sourcingpanel, you will see here the list of available columns from the imported file. - List Value Separator – separator for multi-value fields (Multi-value List, Array)
- Field delimiter for relation – separator for fields of related records
- Thousand separator – optional thousand separator symbol. Numerical values without thousand separator will also be imported (e.g., both values 1234,34 and 1.234,34 will be imported if "." is defined as a thousand separator).
- Decimal mark – decimal separator. Usually
.or,should be defined here. - Marker for Empty Value – symbol interpreted as empty value, in addition to the empty cell
- Marker for Null Value – symbol interpreted as NULL
- Marking for No Relation – symbol for unlinked relations
- Marker for Skipped Value – symbol to skip during import, regardless of whether it is a field or a relation
- Repeated data record processing – duplicate handling:
- Generate mistake for repeated records – error on duplicates
- Allow repeated data record processing – process duplicates. For feeds of type "Update", this results in existing data being replaced with the last processed value. If your feed allows creating new records, both duplicate records will be created.
- Skip repeated data records – ignore duplicates
All marker and separator symbols must be different.
Configurator
The configurator displays field mapping rules for data import. Initially empty, it populates after saving the import feed.
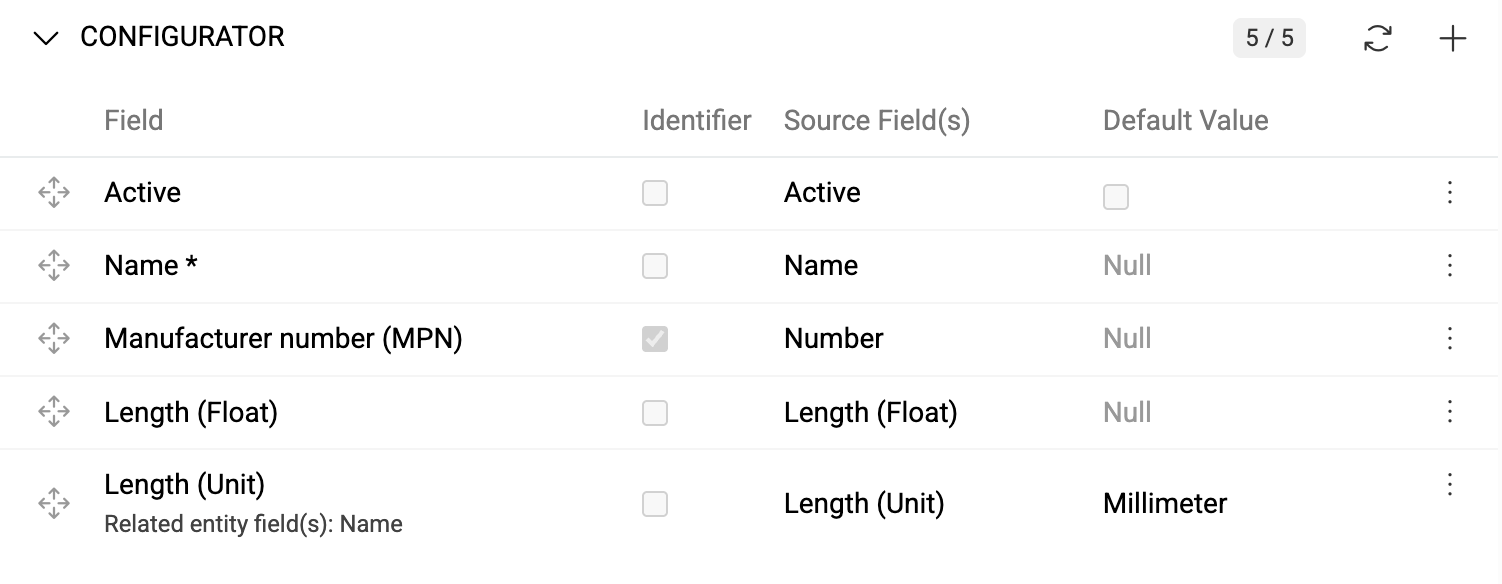
Click + to create mapping rules and fill the pop-up window:
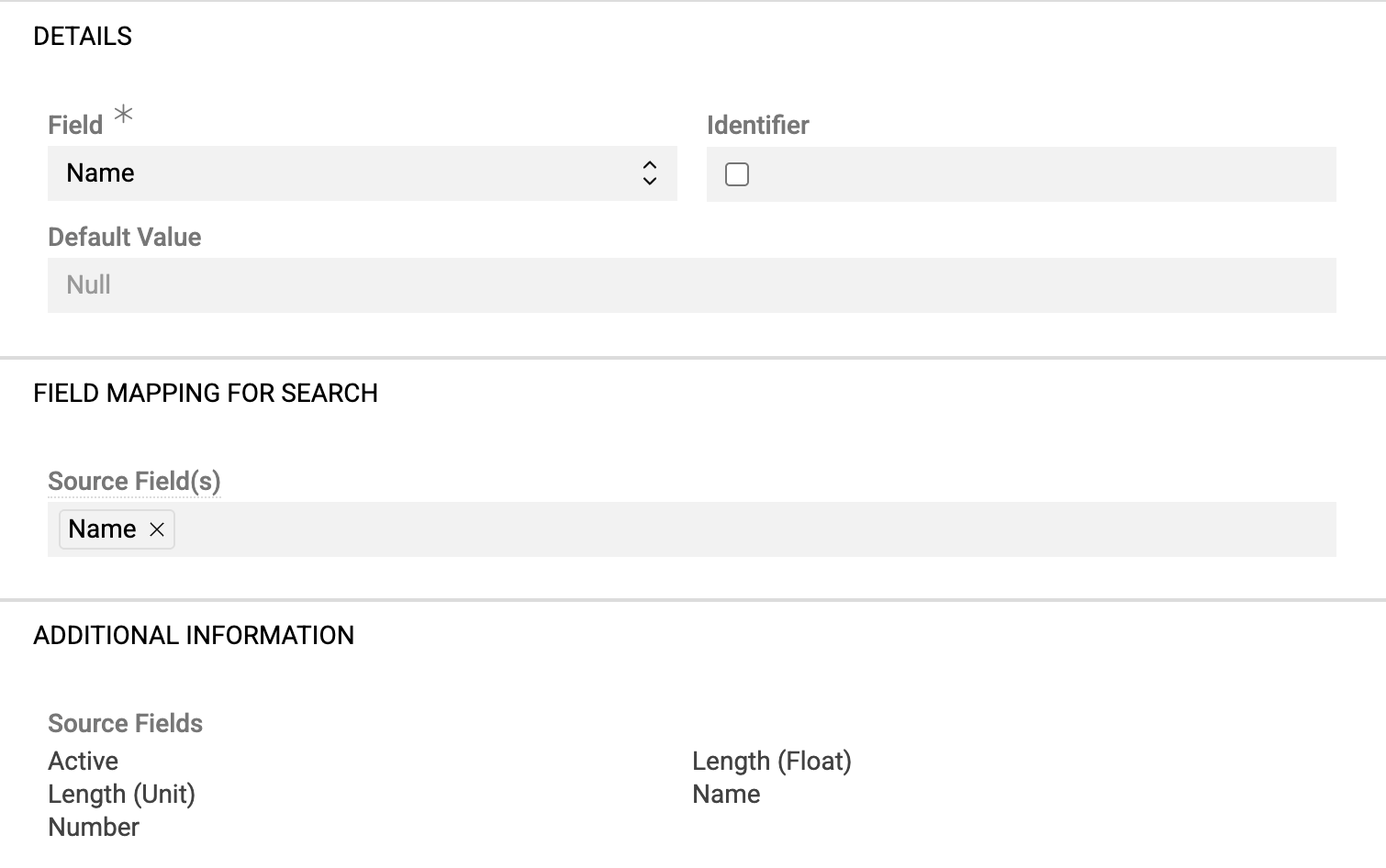
- Field – target field or attribute for the selected entity
- Identifier – marks the column value as an identifier
- Default Value – value used when cell is empty, "empty", or "null"
- Source Field(s) – source columns for data
Columns can be used multiple times in different rules.
Use single record actions to edit or delete mapping rules.
Identifier
Define which fields serve as identifiers for record matching. Multiple identifiers can be selected and are used together for database searches. If no identifier is selected, only new records can be created (updates require identifiers).
Default Value
Set default values for fields when source data is empty. Default values can be used without source fields to apply the same value to all records (e.g., assigning all products to a specific catalog).
Attributes
Available for entities with enabled attributes. Select [Add attribute] to choose required attributes, which appear as dropdown options.
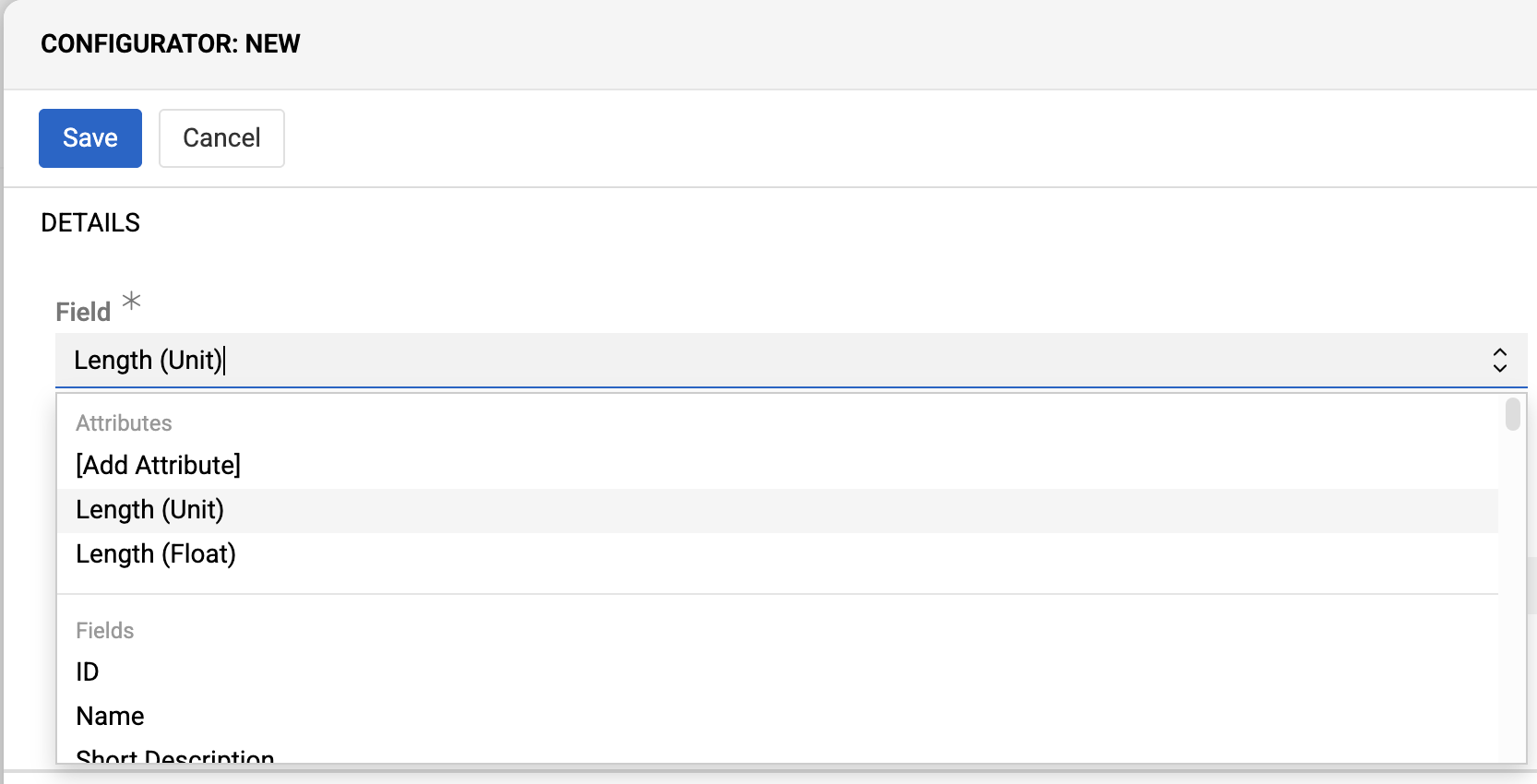
Configure attributes like regular fields.
Marking Attributes as Not Linked
When importing entity fields and attributes simultaneously, use Marker for Unlinked Attribute to explicitly mark attributes that should not be linked to records. Default: N/A.
Example using --- as marker:
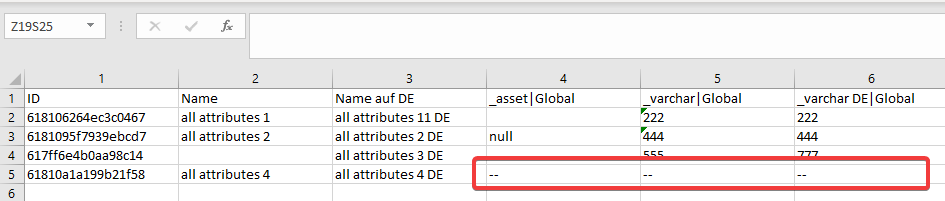
Record "all attributes 4" will not have attributes "_asset", "_varchar", and "_varchar DE" linked.
Boolean Fields and Attributes
For Boolean fields/attributes:
0andFalse(case-insensitive) → FALSE1andTrue(case-insensitive) → TRUE- Empty values → FALSE (when NULL not allowed for a field/attribute)
Range Fields and Attributes
For Integer Range and Float Range fields and attributes, values must be imported from two separate columns in your source file:
- One column for the
Fromvalue (minimum value) - One column for the
Tovalue (maximum value)
In the configurator, it is needed to create two separate mapping rules for each Range field/attribute: select your Range field or attribute and choose field name (From) and field name (To).
Multi-value List and Array Fields
Import Multi-value list and Array values using List Value Separator:
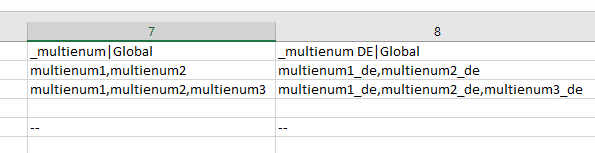 .
.
Invalid values cause the entire row to be skipped.
Fields with Measure Units
Numeric/string fields with measure units accept values like "9 cm", "110,50 EUR", "100.000 USD".
Configure two mapping rules: one for the numeric/string part and one for the unit part.

You can also define a Value Extractor for each part using regular expressions to extract numeric values and units from complex input strings. Enter the pattern without delimiters:
[\d\.,-]+→ extracts float part (e.g., 45.5 from "45.5 EUR")[^\d,.\s]+$→ extracts unit (e.g., EUR from "45.5 EUR")
Non-matching values are treated as empty.
Relations
Import feeds support all relation types: one-to-many, many-to-one, and many-to-many. Related records can be found and linked or created during import.
Configure relations by selecting the relation name as the "Field". Choose search fields for finding related records (ID, Code, Name, etc.).
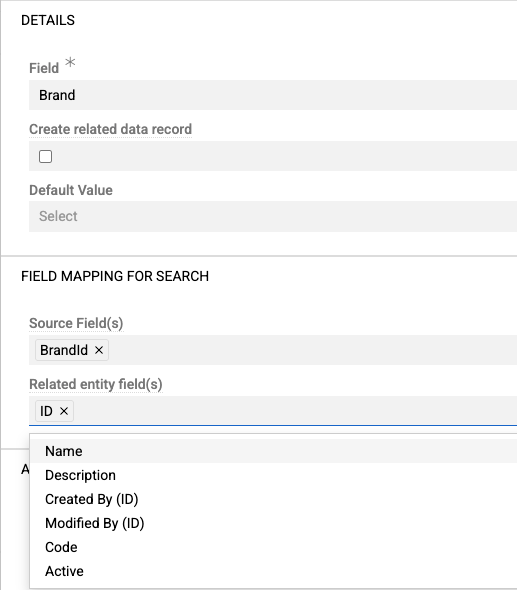
To create missing related records, enable "Create related data record" and configure "Fields mapping for insert":
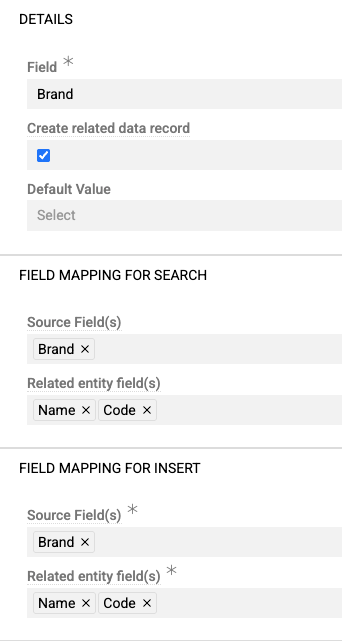
Use Field delimiter for relation to separate field values in CSV cells if all data for a related record is placed in one cell:

If related record creation fails (for example, if required fields are missing), the entire row import fails.
Multiple Relations
Multiple relations work like simple relations but allow creating multiple relations simultaneously. Separate related records using List Value Separator.
Example for many-to-many product-category relations, where both products belong to categories "One" and "Two" (using the default ~ separator):

Configure related entity fields in mapping rules. Use List Value Separator to distinguish different records and Field delimiter for relation to separate fields within each record.
Missing related records can be created using "Fields mapping for insert" settings. If any relation cannot be found and creation is disabled, the entire row is skipped.
All relations must be provided in import data. Missing relations will be unlinked from existing records.
Example: Product A is linked with Category A. Via import feed, you provide Category B and Category C as relations for this product. After the import, Category B and C will be linked with Product A, and Category A will be unlinked because it was not provided in the import file.
Related Files
Recommended approach: Import files separately using Files entity import feed, then link via identifiers during target entity import.
For URL-based file imports, configure the URL field rule. The 'Request headers' panel becomes available for authentication:
Exception: Product Main Image can be imported with product data. Provide image URL in the "Main Image" field, which will both create the file record and set it as the main image.
How To Import List Options
List options can be imported into the system using import data from any type of Data Sourcing. This enables users to create or update multiple options at once.
The import data should contain:
- A list of option values
- A reference to the List each option belongs to (required only when creating new options or updating list assignments)
Target entity should always be List Option. Each row represents a single List Option record.
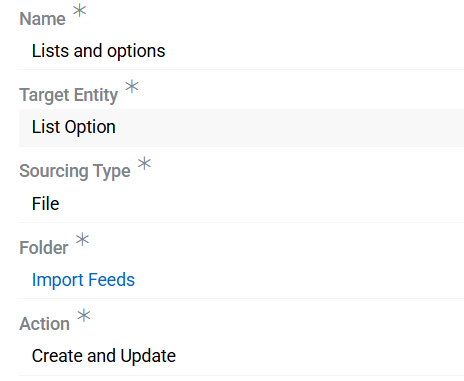
To correctly match existing records during import, it is recommended that system IDs of list options are used as unique identifiers when updating existing options in the list. If all option values are unique within the system, however, the option value (name) can be used as an identifier instead. The example feed configuration is shown in the image below:
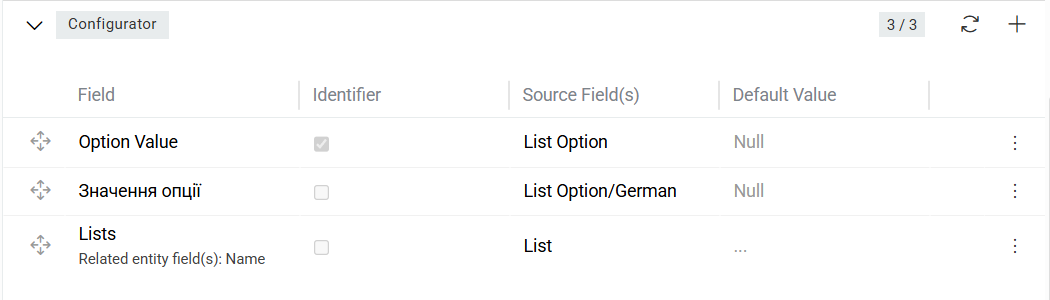
When creating new list options it is recommended to link options to their corresponding lists within the same import feed usung multiple relations method. This ensures that all required relationships are established during the import process and prevents orphaned option records.
Running Import Feed
Click Import to process the configured sample file:
Or use Upload & Import to import a new file with the same structure:
Import jobs appear in the Job Manager with current status. Errors are displayed there as well.
Executions are added to the "Import Executions" panel with Pending status, changing to Success upon completion.
Cancel running imports via the right-side menu:
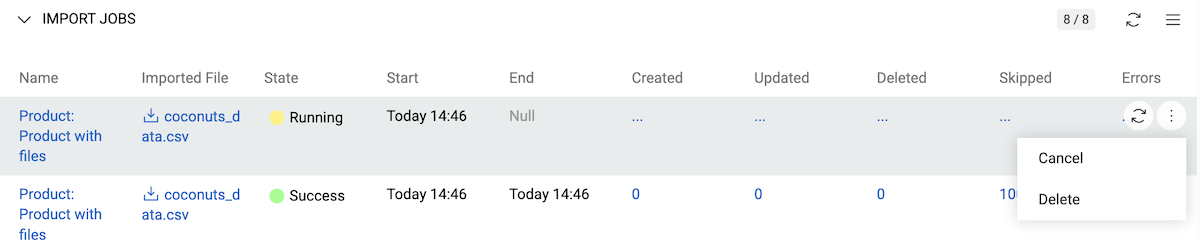
View last execution time and status on import feed details and list views:

Import Executions
Import execution results are displayed in two locations:
Import Executions panel (on the respective import feed):

Import Executions list view (all system import executions):
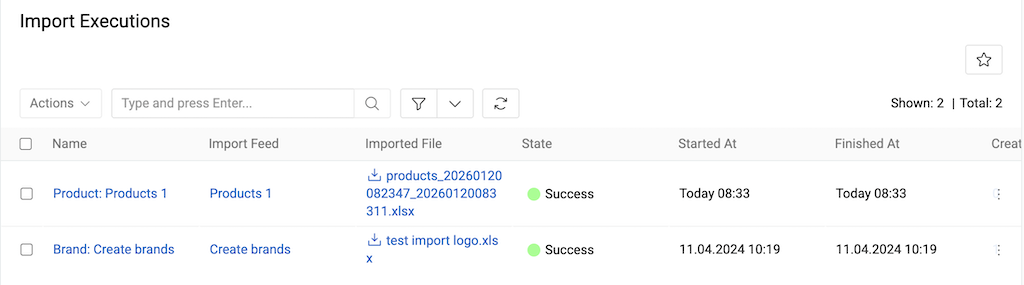
Execution details include:
- Name – auto-generated execution name (click to open detail view)
- Import feed – source import feed name
- Imported file – data file name (click to open/download)
- State – current execution status
- Start At/Finished At – execution timestamps
- Created/Updated/Deleted/Skipped – record counts (click to view filtered lists)
- Errors – error count (click to view error details)
While the import is running, counters for created, updated, or deleted records are not updated live. Click the Refresh button next to a running execution to view the latest counts.
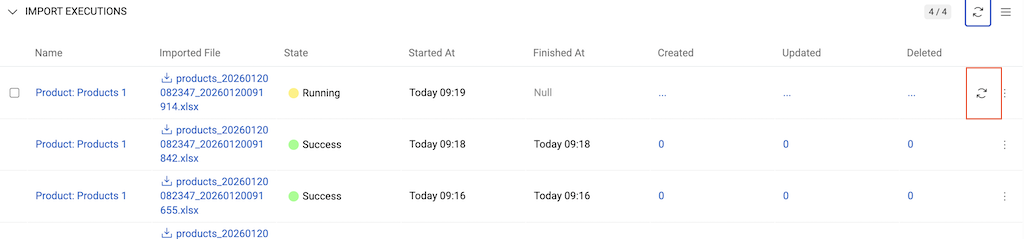
Execution States:
- Running – currently executing
- Pending – queued for execution
- Success – completed (may contain errors)
- Failed – technical failure
- Canceled – user-stopped
Use single record actions to recreate executions or remove them.
The Recreate action starts a new import using the same file from the selected execution. This is helpful if you imported a large file that created multiple executions and need to rerun only those that encountered errors.
Import Execution Details
Click execution name to view details:
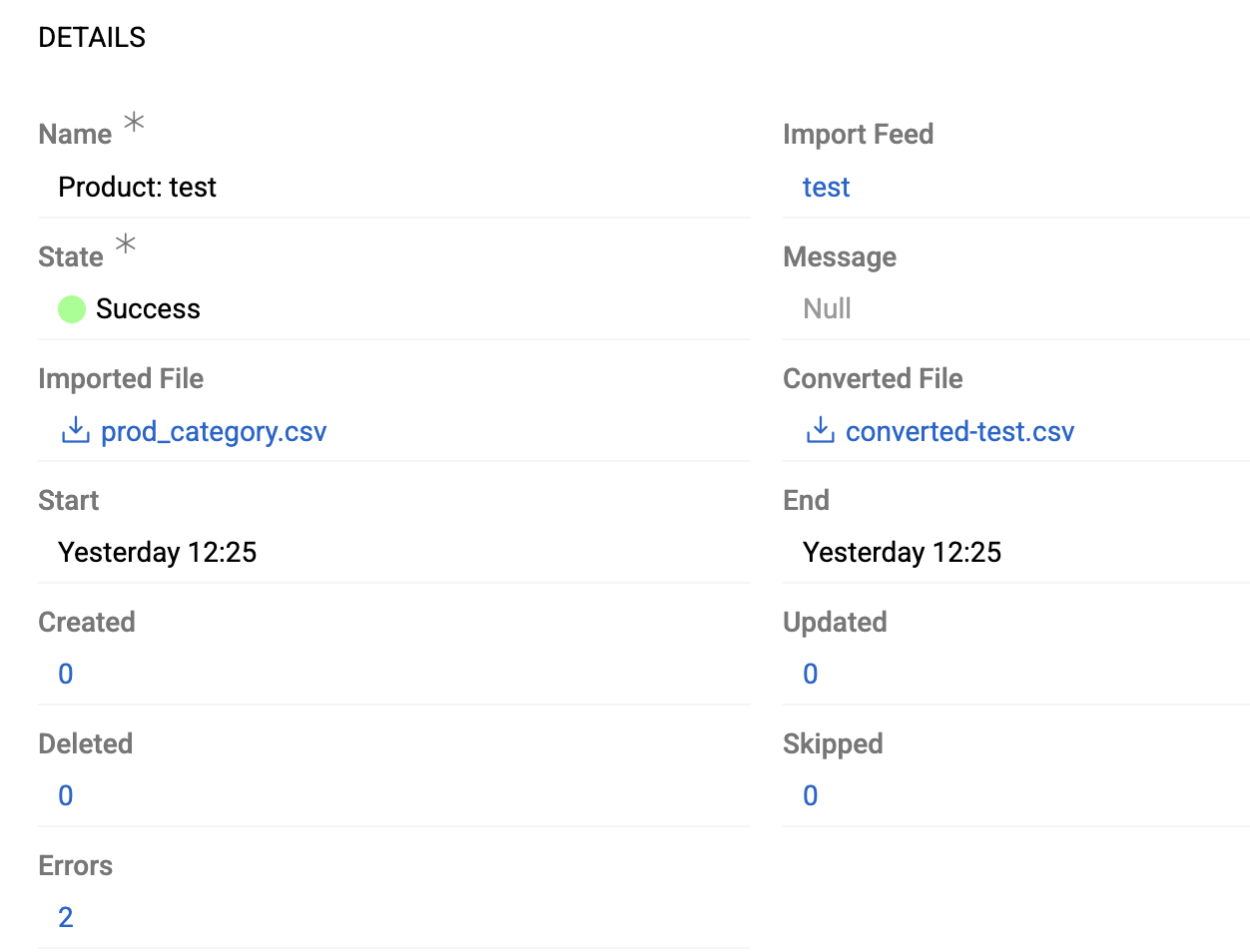
Error messages, if any, appear in the Errors log panel:
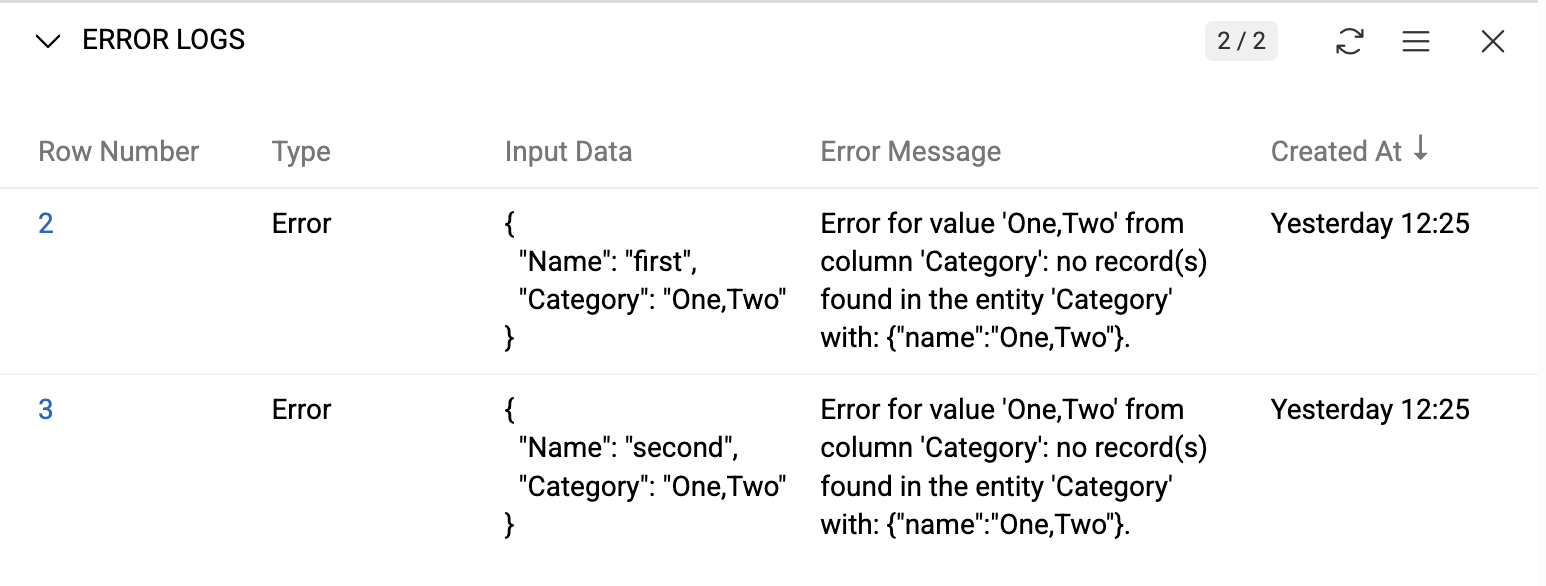
Use Show List action to view all error records filtered by current execution.
Generate Files with Import Results
To review exactly what was imported, click the file name in your Import Executions record to download the original imported file. You can also download the converted file from the Import Execution, which contains the final data that was imported after applying the import script.
For each Import execution, you can download result files for created, updated, and deleted records. Files are also available for records skipped by the import script or the system, and for any import errors.
To generate a file, open the execution's record actions menu and choose the type of result file you wish to download.
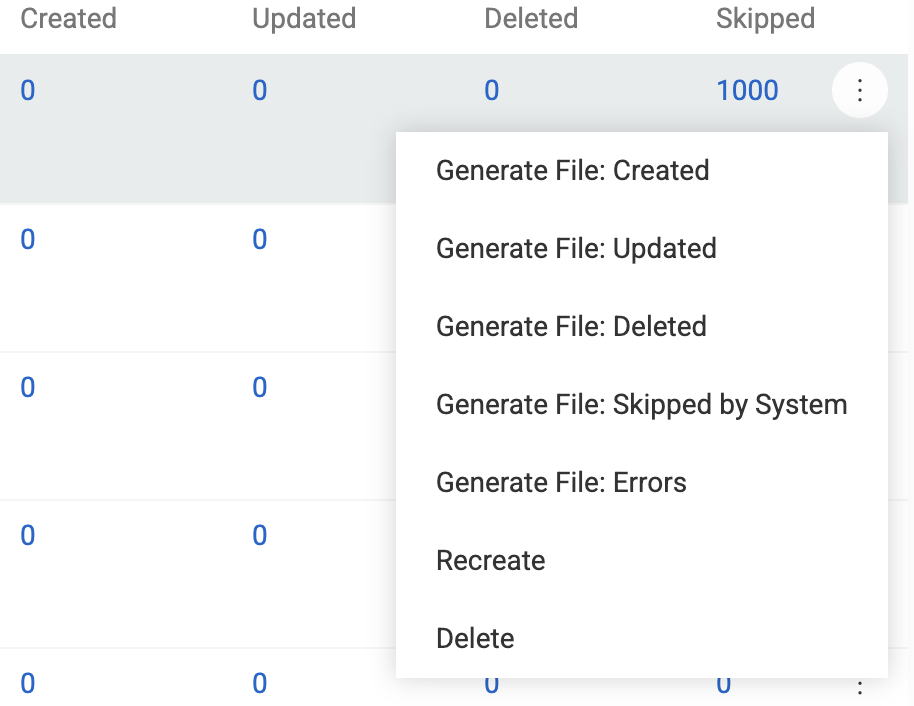
Files download immediately and are linked in the job's Files panel.
Files generated during import are linked to both their Import Feed and Import Execution (field name Import Job). You can view or filter files by these fields in the File entity to trace their origin.
Error File
Import data is validated using the same rules as manual record creation. Errors occur for:
- Missing required field values
- Wrong data types (e.g., string in Boolean field)
- Invalid field values
- Missing relations
Import processes rows completely or skips them entirely. Failed rows appear in error files with Reason column explaining the failure.
Processing of a row stops at the first error detected, so an error file shows only one message per row—even if there are additional errors.
Generate error files to download, correct data, and reimport.
Import Feed Actions
Standard record management actions are available, including duplicate and remove.
Duplicate copies all values and mapping rules to a new import feed.
Copy Configurations exports configuration as JSON. See Copying Feed Configurations for details.
Creating Import Feed from Export Feed
With the Export Feed module installed, create import feeds from export feeds using Duplicate as import:
This creates a new import feed with matching fields, format, entity, and mapping rules. Action defaults to "update only" with "(From Export)" suffix in the name.
If an export feed is copied as an import feed, the export rule for all attributes is skipped.
Mapping rules for protected fields are excluded, as protected fields cannot be imported.